Suchir Balaji asks: Is it Fair Use to train large language models on copyrighted content?
The legal future of OpenAI’s ChatGPT and nearly every other large language model (LLM) depends on one question: when a large language model “reads” and “learns” from copyrighted content, is that action protected by the Fair Use provisions of copyright law?
Vendors of LLMs insist that training their products on the open web is no different from humans reading content. After all, when you read a web page or a document, you’re basically making a copy of it line-by-line in your eyes and in your brain. It’s also presumably legal to use a digital viewer to enlarge the content to read it. So long as you don’t make and keep a copy, that should be fine.
Opponents of this view insist that copyright holders — authors and their licensees — have the right to control how their content is used. They should be able to hold their content out of collections used for AI training, or insist to get paid to license it.
Unfortunately, both of these perspectives are clouded by “motivated reasoning” — that is, proponents of each view start with the conclusion they feel is “natural” and reason backwards to show they’re right.
At the center of this conundrum is the question, “Is training an AI on copyrighted data Fair Use, as the law defines that term?” If it’s Fair Use, it’s legal. If it’s not, it’s a violation of the copyright holders’ rights.
This is not a question of whether technology makers are allowed to bend rules to “disrupt” markets, or of moral or ethical rights. It’s a legal question. And the judges who must eventually decide this issue need a more sober and logical perspective.
Suchir Balaji has done the homework on the Fair Use question
From time to time I’ve made the quip that Fair Use is when I use your content, and a copyright violation is when you use mine. But of course, legally, there’s a lot more to it.
Suchir Balaji, a former researcher at OpenAI who was at one point tasked with organizing the training data for the predecessors of ChatGPT, has carefully considered this. He left OpenAI in 2022 after concluding that OpenAI wasn’t appropriately respecting the copyrights of the content it consumed.
Now he has put together a detailed analysis on his blog that he claims proves that OpenAI’s use of online content does not qualify as Fair Use.
Here’s how the Copyright Act of 1976 defines Fair Use:
. . . the fair use of a copyrighted work, including such use by reproduction in copies or phonorecords or by any other means specified by that section, for purposes such as criticism, comment, news reporting, teaching (including multiple copies for classroom use), scholarship, or research, is not an infringement of copyright. In determining whether the use made of a work in any particular case is a fair use the factors to be considered shall include—
- the purpose and character of the use, including whether such use is of a commercial nature or is for nonprofit educational purposes;
- the nature of the copyrighted work;
- the amount and substantiality of the portion used in relation to the copyrighted work as a whole; and
- the effect of the use upon the potential market for or value of the copyrighted work.
Balaji’s analysis looks as all four factors. And for the purposes of this discussion, note that all four factors have weight: an actor does not need to prove all four to claim Fair Use, nor can they show just one. Courts will take all four into account.
Factor 1. Are LLMs commercial or educational/nonprofit?
When OpenAI was primarily a nonprofit research organization, you could argue that this factor helped protect what it was doing. It’s the argument put forth by the Internet Archive, for example. But LLMs are now being valued in the hundreds of billions of dollars. So I think this “noncommercial” argument is in now in tatters.
As Balaji points out, the Supreme Court has ruled that there are exceptions for work that is “transformative.” If Andy Warhol paints a bunch of copies of someone else’s photograph (and yes, that was a real case), you can at least potentially argue he’s transformed it into art, not just copied it. (But Warhol’s foundation lost at the Supreme Court.)
This is a challenging question for LLMs. By combining information from many sources, they do in a sense transform the content of those sources. If I tell ChatGPT to describe Trump’s position on tariffs in the form of a sonnet, it’s certainly transforming original sources that don’t talk that way.
In markets fierce, his views provoke a storm,
Yet in his eyes, this path will keep us warm.On tariffs, Trump stands firm with steel resolve,
He seeks to shield the nation’s prized domain.
To foreign goods, his stance does not absolve,
He raises walls to ease domestic strain.He claims these taxes keep our workers strong,
Protecting jobs from lands that undercut.
Though critics say his measures lead to wrong,
He presses on, his rhetoric clear-cut.For trade, he fights, the balance he desires,
With tariffs high, he argues for the gain.
He sees in them a tool that still inspires,
To make our nation great, secure its reign.
Factor 2: What is the nature of the copyrighted work used by the LLM?
LLM developers prefer high quality training data, such as books and subscription-based news sites. But high-quality training data tends to be firmly protected by copyright. So this certainly isn’t going to save the Fair Use argument.
Factor 3: Do LLMs use the whole of copyrighted works?
According to Balaji, factor 3 (substantiality) legally boils down to two sides of the argument:
- The inputs of the model are full copies of copyrighted data, so the “amount used” is the entirety of the copyrighted work. This would weigh against “fair use”.
- The outputs of the model are almost never copies of copyrighted data, so the “amount used” is almost zero. This could potentially weigh in favor of “fair use”.
I must admit to being charmed by this technical illustration intended to answer the question, “Are AI models just regurgitating the stuff they ingest?”
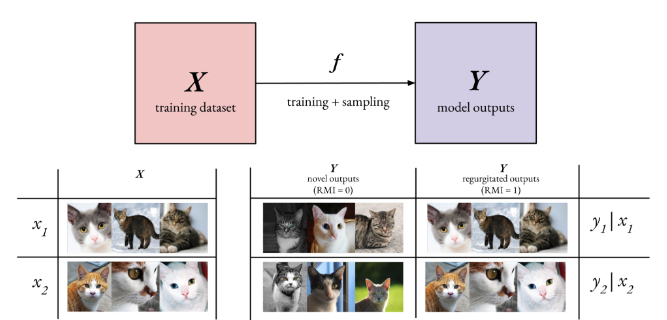
The point here is, based on the training choices and how the model is tuned, it can often be stimulated to “cough up” nearly complete copies of the data on which it was trained. That’s the core of the New York Times‘s case against OpenAI.
Factor 4: Do LLMs interfere with the market for copyrighted content
As Balaji points out, there’s pretty good evidence that AI is undermining the market for copyrighted content. For example, traffic to Stack Overflow declined 12% after ChatGPT became public. It’s a lot easier to get an answer from ChatGPT than to search for and track it down on Stack Overflow. The same is true of many other sites. If you’ve used a Google search and seen the answer delivered by Google Gemini, rather than viewing a web site from which that answer was retrieved, you’re an instance of reduced traffic –and therefore, the market — to a piece of content.
When I asked ChatGPT “How does Josh Bernoff explain that passive voice is ineffective writing?”, it answers this way:
Josh Bernoff argues that passive voice weakens writing because it makes sentences less clear and harder to follow. In his view, passive constructions hide the subject of the action, making the sentence vague and less engaging. He believes active voice is more direct and powerful because it clearly shows who is performing the action, making the writing more compelling and easier to understand.
Now you don’t need to read my book or my blog posts, you can get my opinion secondhand from ChatGPT. That’s eroding the market for my content.
Conclusion: the Fair Use arguments in support of LLMs are weak
Balaji is convinced that since LLMs fail in all four Fair Use factors, they’re toast, from a legal perspective. Pay a license or get sued out of business, basically.
I don’t find it quite so clear-cut. But again and again, the “transformative” element of LLMs tends to fail: some part of what they generate is just full copies of things that already exist. They’re not consistently transformative.
While I don’t think it’s as black-and-white as Balaji says, I do think that the LLM vendors will have a great deal of difficulty asserting Fair Use over a tool that reads the entire internet, wholesale, and then provides copies of what it reads with various levels of fidelity and variation. That activity is going to take a whole lot of money to defend.
Of course if there’s one thing these vendors have, it’s a whole lot of money. So this sideshow will certainly go on for at least the next few years before we get any kind of definitive decision.
Josh
Until I read your post today I’d thought that training LLM products on the open web was no different from humans reading content. But that was because I didn’t understand what Fair Use is. Thanks for setting me straight on this.
Though I understand the overall message of the technical illustration that charmed you, I do have two questions.
What is the origin of the illustration?
What does RMI mean – Regurgitated Material Input, perhaps?
Tom
The graphic is in Balaji’s blog, linked in my post. I don’t claim to understand all of it.