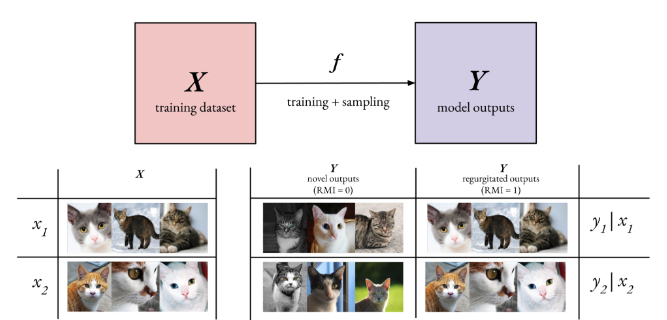
Suchir Balaji asks: Is it Fair Use to train large language models on copyrighted content?
The legal future of OpenAI’s ChatGPT and nearly every other large language model (LLM) depends on one question: when a large language model “reads” and “learns” from copyrighted content, is that action protected by the Fair Use provisions of copyright law? Vendors of LLMs insist that training their products on the open web is no…